Neste primeiro momento, estruturamos os dados do nosso experimento. Avaliamos um total de 8 parcelas (plantas), divididas igualmente em dois tratamentos: um grupo controle e um grupo submetido à aplicação de fungicida. A variável resposta analisada é a severidade da doença (em porcentagem).
Abaixo, criamos o banco de dados e geramos uma tabela formatada para conferência.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.2.0
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.5 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
dados <-data.frame(planta =seq(1:8),tratamento =c("controle", "controle", "controle", "controle", "fungicida", "fungicida", "fungicida", "fungicida"),severidade =c(42, 38, 45, 40, 12, 18, 15, 10))knitr::kable(dados) # Gera uma tabela formatada no documento
planta
tratamento
severidade
1
controle
42
2
controle
38
3
controle
45
4
controle
40
5
fungicida
12
6
fungicida
18
7
fungicida
15
8
fungicida
10
##Visualização dos dados
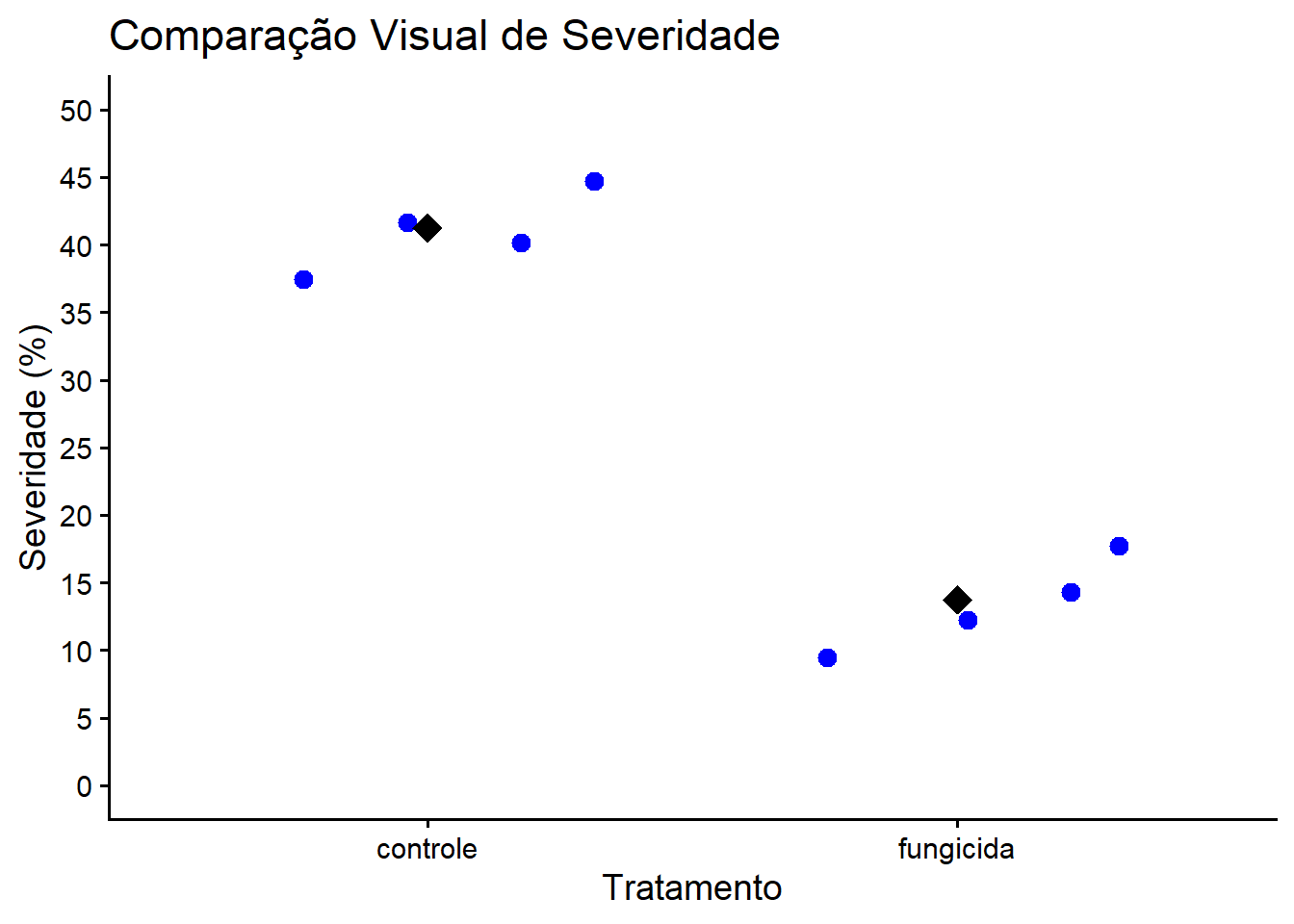
A visualização gráfica é essencial para entender a distribuição dos dados antes da análise estatística. Criamos um gráfico de dispersão com os pontos observados (em azul). O losango preto representa a média de severidade de cada tratamento.
Visualmente, podemos notar uma redução drástica na severidade da doença no grupo tratado com fungicida.
library(ggplot2) ggplot(dados, aes(x = tratamento, y = severidade))+geom_jitter(color ="blue", size =3) +ylim(0, 50) +theme_classic(base_size =14) +labs(x ="Tratamento", y ="Sev (%)")+stat_summary(fun ="mean", geom ="point", shape =18, size =5, color ="black")+scale_y_continuous(limits =c(0, 50), breaks =seq(0, 50, by =5)) +theme_classic(base_size =14) +labs(x ="Tratamento",y ="Severidade (%)",title ="Comparação Visual de Severidade" ) +theme(legend.position ="none")
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Análise Estatística Para confirmar se a diferença observada no gráfico é estatisticamente significativa, aplicamos um Teste T de Student para duas amostras independentes. Assumimos que as variâncias entre os grupos são homogêneas (var.equal = TRUE).
resultado <-t.test(severidade ~ tratamento, data = dados, var.equal =TRUE)resultado
Two Sample t-test
data: severidade by tratamento
t = 11.955, df = 6, p-value = 2.076e-05
alternative hypothesis: true difference in means between group controle and group fungicida is not equal to 0
95 percent confidence interval:
21.87122 33.12878
sample estimates:
mean in group controle mean in group fungicida
41.25 13.75
Como o p-valor resultante do teste é extremamente baixo (menor que 0.05), rejeitamos a hipótese nula. Conclui-se que há uma diferença estatisticamente significativa na severidade da doença entre as plantas do grupo controle e as do grupo tratado com fungicida.