Nesta aula, vamos analisar dados de um experimento com milho no qual se avaliou o índice de infecção em diferentes híbridos e métodos de inoculação. O exemplo é útil para discutir três pontos importantes em experimentação agrícola:
a estrutura de um delineamento com parcelas subdivididas;
a diferença entre uma ANOVA clássica com estratos de erro e um modelo linear misto;
o uso de médias ajustadas, comparações múltiplas e gráficos interpretáveis.
A lógica estatística central é que nem todos os fatores são avaliados com a mesma precisão. Em parcelas subdivididas, o fator aplicado à parcela principal costuma ter um erro experimental diferente daquele aplicado à subparcela. Por isso, o modelo precisa reconhecer a estrutura hierárquica do experimento.
Pacotes
library(readxl)library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.2.0
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.5 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(car)
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
library(lme4)
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Registered S3 method overwritten by 'lme4':
method from
na.action.merMod car
library(lmerTest)
Warning: package 'lmerTest' was built under R version 4.5.3
Attaching package: 'lmerTest'
The following object is masked from 'package:lme4':
lmer
The following object is masked from 'package:stats':
step
library(DHARMa)
Warning: package 'DHARMa' was built under R version 4.5.3
This is DHARMa 0.4.7. For overview type '?DHARMa'. For recent changes, type news(package = 'DHARMa')
library(emmeans)
Warning: package 'emmeans' was built under R version 4.5.3
Welcome to emmeans.
Caution: You lose important information if you filter this package's results.
See '? untidy'
library(multcomp)
Warning: package 'multcomp' was built under R version 4.5.3
Loading required package: mvtnorm
Warning: package 'mvtnorm' was built under R version 4.5.3
Warning: package 'TH.data' was built under R version 4.5.3
Loading required package: MASS
Attaching package: 'MASS'
The following object is masked from 'package:dplyr':
select
Attaching package: 'TH.data'
The following object is masked from 'package:MASS':
geyser
library(knitr)
Usaremos o pacote {readxl} para importar os dados, {tidyverse} para manipulação e gráficos, {car} para o teste de Levene, {lme4} e {lmerTest} para modelos mistos, {DHARMa} para diagnóstico por resíduos simulados, {emmeans} para médias marginais estimadas e {multcomp} para letras de agrupamento.
A análise exploratória não substitui o modelo estatístico, mas ajuda a identificar padrões gerais, possíveis discrepâncias e a escala das variáveis.
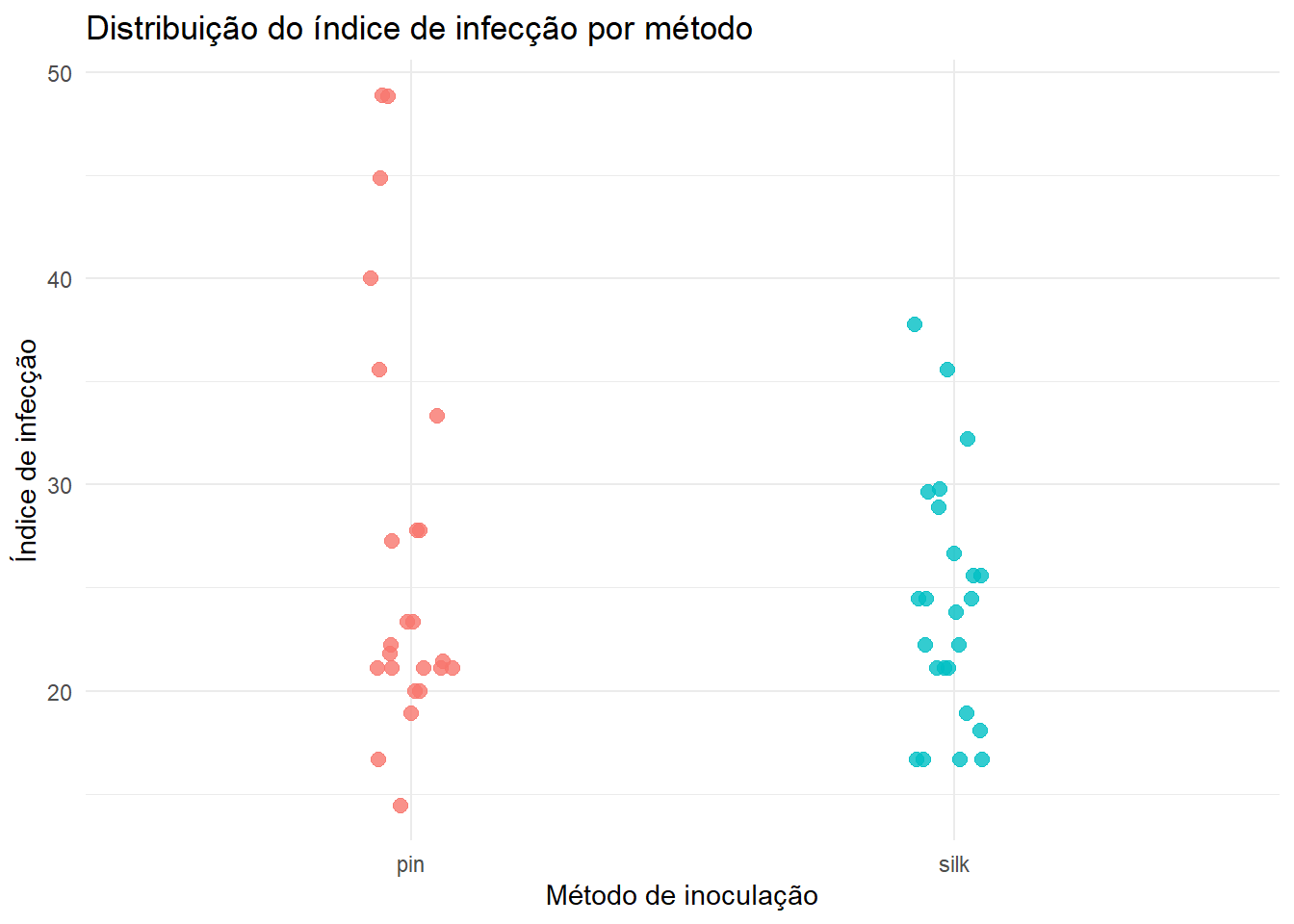
Índice de infecção por método
milho |>ggplot(aes(x = method, y = index, color = method)) +geom_point(position =position_jitter(width =0.08, height =0), size =2.5, alpha =0.8) +labs(x ="Método de inoculação",y ="Índice de infecção",title ="Distribuição do índice de infecção por método" ) +theme_minimal() +theme(legend.position ="none")
O gráfico mostra a distribuição dos valores observados de index para cada método. Como os dados também dependem do híbrido e do bloco, diferenças aparentes entre métodos devem ser interpretadas com cautela nesta etapa.
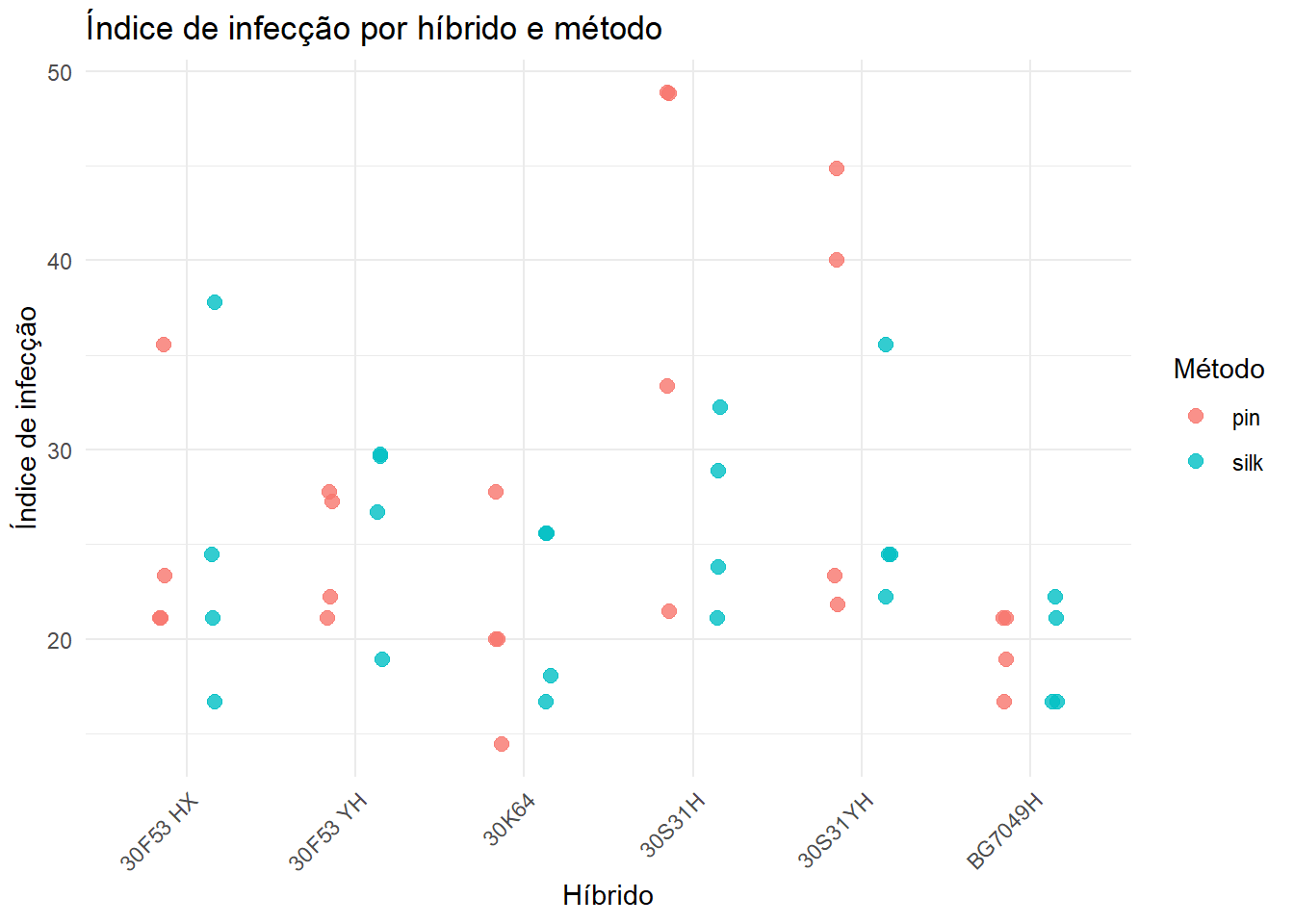
Índice de infecção por híbrido e método
milho |>ggplot(aes(x = hybrid, y = index, color = method)) +geom_point(position =position_jitterdodge(jitter.width =0.08, dodge.width =0.6),size =2.5, alpha =0.8) +labs(x ="Híbrido",y ="Índice de infecção",color ="Método",title ="Índice de infecção por híbrido e método" ) +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
Este gráfico é mais informativo porque mostra simultaneamente os dois fatores de interesse: híbrido e método. Ele também permite antecipar uma possível interação entre híbrido e método. Existe interação quando a diferença entre métodos não é constante para todos os híbridos.
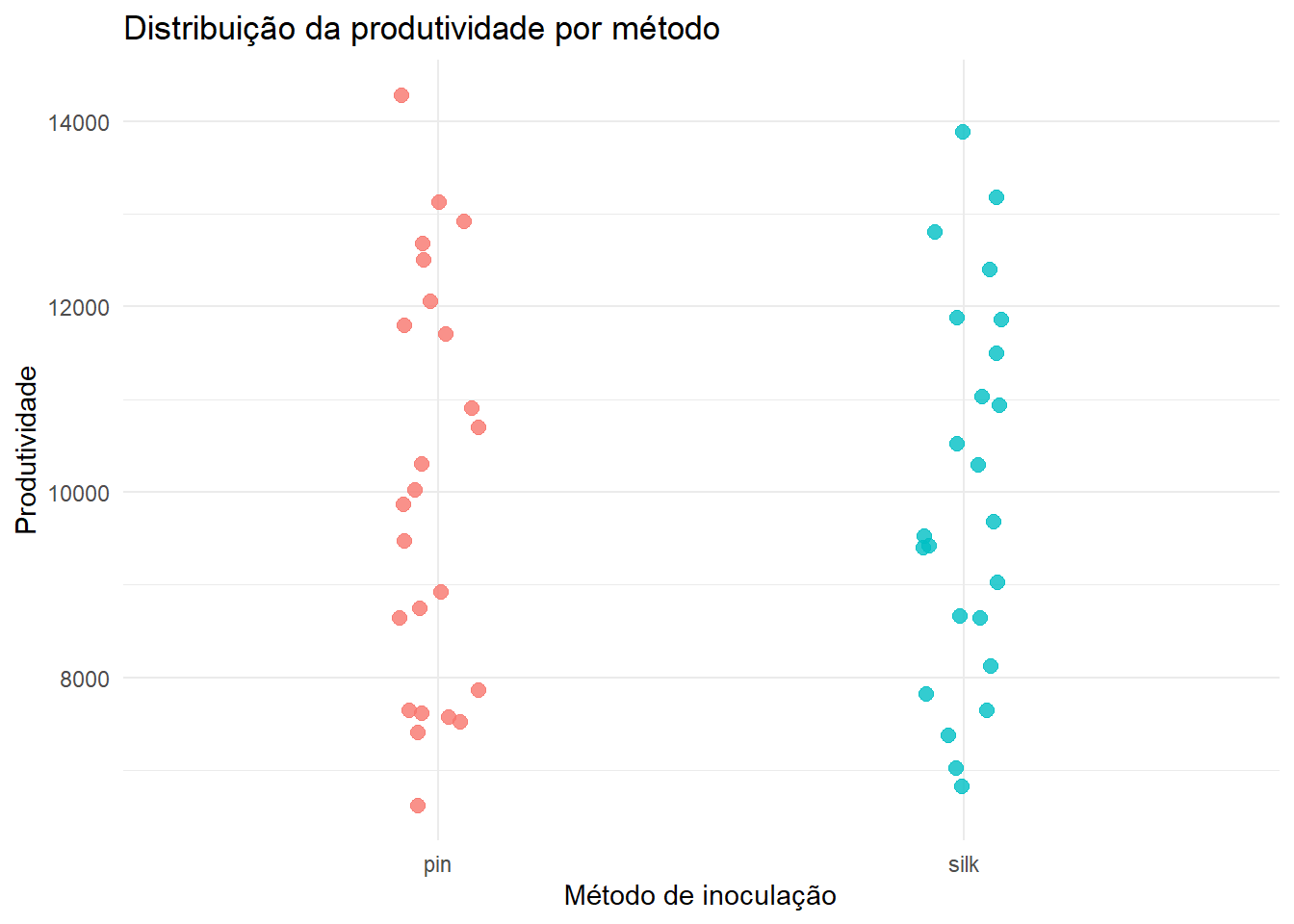
Produtividade por método
milho |>ggplot(aes(x = method, y = yield, color = method)) +geom_point(position =position_jitter(width =0.08, height =0), size =2.5, alpha =0.8) +labs(x ="Método de inoculação",y ="Produtividade",title ="Distribuição da produtividade por método" ) +theme_minimal() +theme(legend.position ="none")
Embora a análise principal desta aula seja feita para index, a variável yield pode ser analisada posteriormente com estrutura semelhante, desde que o objetivo biológico seja claramente definido.
Delineamento em parcelas subdivididas
Neste experimento, a estrutura estatística pode ser representada como um delineamento em parcelas subdivididas. Em termos práticos:
os blocos representam fontes de variação controladas no campo;
os híbridos são atribuídos às parcelas principais;
os métodos são avaliados dentro das parcelas principais, nas subparcelas;
a interação hybrid:method indica se o efeito do método depende do híbrido.
A principal consequência estatística é que há dois níveis de erro:
erro da parcela principal, associado à comparação entre híbridos;
erro da subparcela, associado ao método e à interação híbrido × método.
Essa formulação explicita que existem componentes de variância diferentes para blocos, parcelas principais e subparcelas.
ANOVA clássica com aov()
A função aov() permite especificar estratos de erro usando Error(). Para parcelas subdivididas, podemos usar Error(block/hybrid), que informa ao R que híbridos estão associados ao estrato de parcelas principais dentro de blocos.
Error: block
Df Sum Sq Mean Sq
block 3 592.2 197.4
Error: block:hybrid
Df Sum Sq Mean Sq F value Pr(>F)
hybrid 5 974.2 194.84 3.14 0.0389 *
Residuals 15 930.9 62.06
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
method 1 79.61 79.61 4.726 0.0433 *
hybrid:method 5 265.28 53.06 3.150 0.0324 *
Residuals 18 303.18 16.84
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
A expressão hybrid * method é equivalente a:
hybrid + method + hybrid:method
Portanto, o modelo testa:
efeito principal de híbrido;
efeito principal de método;
interação híbrido × método.
Em parcelas subdivididas, o teste para híbrido deve usar o erro da parcela principal. O teste para método e para a interação híbrido × método usa o erro da subparcela. Esse é o motivo pelo qual o modelo apresenta mais de um estrato de erro.
Pressupostos do modelo
Os principais pressupostos de modelos lineares para ANOVA são:
independência dos erros;
normalidade aproximada dos resíduos;
homogeneidade de variâncias;
estrutura correta do delineamento.
A independência depende principalmente do delineamento e da condução do experimento. Normalidade e homogeneidade podem ser avaliadas com gráficos e testes auxiliares.
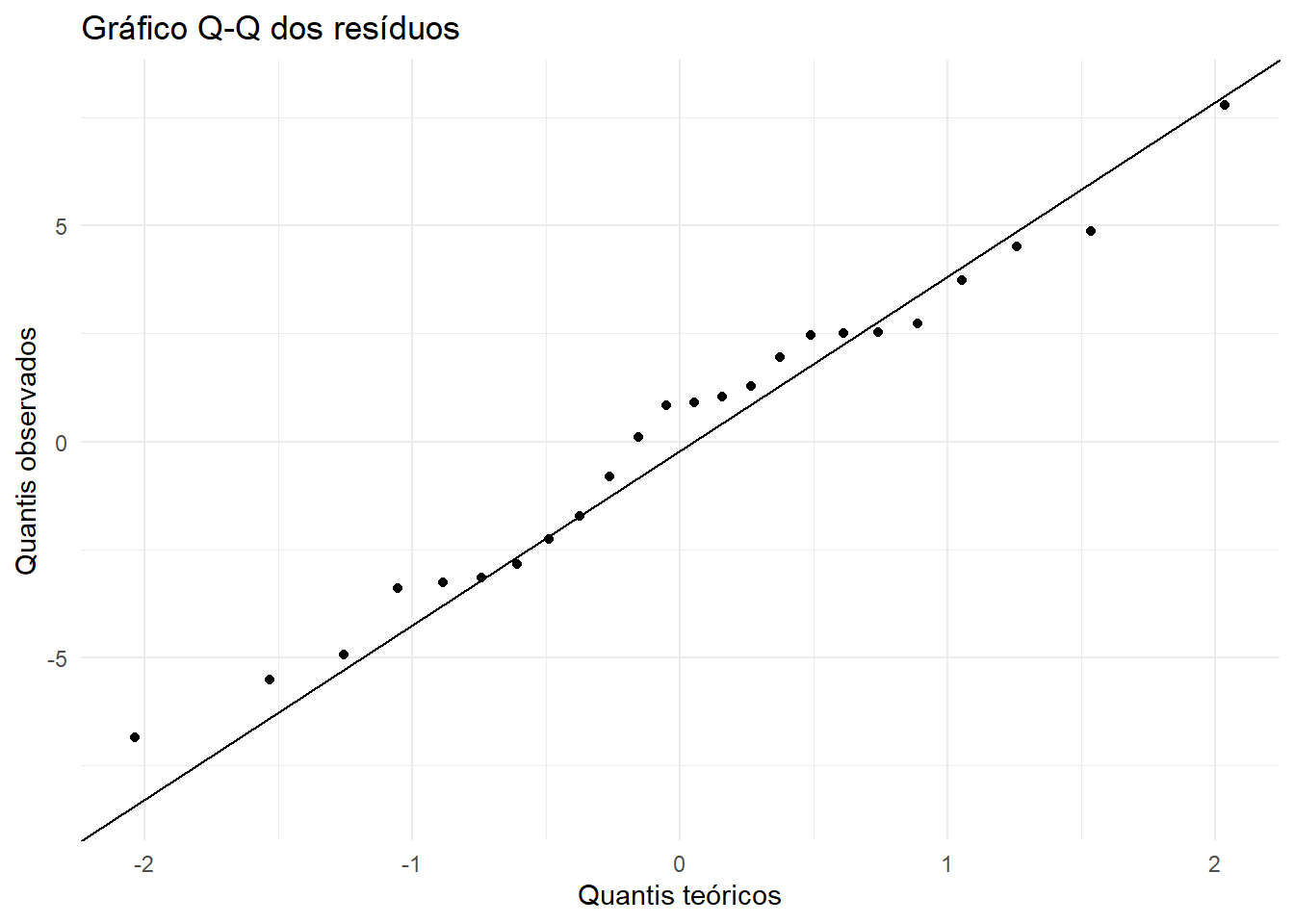
Extração dos resíduos
No objeto produzido por aov() com estratos de erro, os resíduos ficam armazenados por estrato. Para o diagnóstico da subparcela, extraímos os resíduos do estrato Within.
\[
H_A: \text{os resíduos não seguem distribuição normal}
\]
shapiro.test(residuos)
Shapiro-Wilk normality test
data: residuos
W = 0.9801, p-value = 0.8978
Um valor de \(P\) pequeno sugere evidência contra a normalidade. Entretanto, em amostras pequenas, o teste pode ter baixa potência; em amostras grandes, diferenças pequenas podem gerar valores significativos. Por isso, o teste deve ser interpretado junto com gráficos de diagnóstico.
Se os pontos seguem aproximadamente a reta, a suposição de normalidade é considerada razoável para fins práticos.
Homogeneidade de variâncias
A homogeneidade de variâncias significa que a variabilidade residual é aproximadamente semelhante entre os grupos comparados. O teste de Levene avalia essa condição.
leveneTest(index ~ hybrid * method, data = milho)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 11 2.1493 0.04152 *
36
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
em que \(g\) é o número de combinações entre híbridos e métodos.
Neste exemplo, usamos a combinação hybrid * method porque a unidade comparativa final envolve os tratamentos formados pela combinação entre os dois fatores. Como o delineamento é hierárquico, o teste de Levene deve ser visto como diagnóstico auxiliar, não como substituto da modelagem correta.
Modelo linear misto
A abordagem com modelos mistos é geralmente mais flexível para experimentos com estrutura hierárquica. Aqui, híbrido, método e sua interação são tratados como efeitos fixos, pois representam os tratamentos de interesse. Bloco e parcela principal dentro de bloco são tratados como efeitos aleatórios.
index ~ hybrid * method: efeitos fixos de híbrido, método e interação;
(1 | block): intercepto aleatório para bloco;
(1 | block:hybrid): intercepto aleatório para a parcela principal, isto é, cada combinação bloco × híbrido.
Esse modelo reconhece que observações dentro da mesma parcela principal tendem a ser mais semelhantes entre si do que observações de parcelas diferentes.
ANOVA do modelo misto
anova(modelo_misto)
Type III Analysis of Variance Table with Satterthwaite's method
Sum Sq Mean Sq NumDF DenDF F value Pr(>F)
hybrid 264.409 52.882 5 15 3.1397 0.03891 *
method 79.606 79.606 1 18 4.7263 0.04329 *
hybrid:method 265.281 53.056 5 18 3.1500 0.03240 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
A tabela de ANOVA do modelo misto fornece testes para os efeitos fixos. O pacote {lmerTest} adiciona aproximações para graus de liberdade e valores de \(P\), frequentemente usando métodos como Satterthwaite ou Kenward-Roger, dependendo da configuração.
A interpretação segue a ordem lógica:
primeiro verificar se a interação hybrid:method é relevante;
se a interação for importante, interpretar o efeito de método dentro de cada híbrido e o efeito de híbrido dentro de cada método;
se a interação não for importante, os efeitos principais podem ser interpretados de forma mais direta.
O resumo do modelo mostra os componentes de variância dos efeitos aleatórios. Esses componentes indicam quanto da variação total é atribuída a:
diferenças entre blocos;
diferenças entre parcelas principais dentro de blocos;
variação residual entre subparcelas.
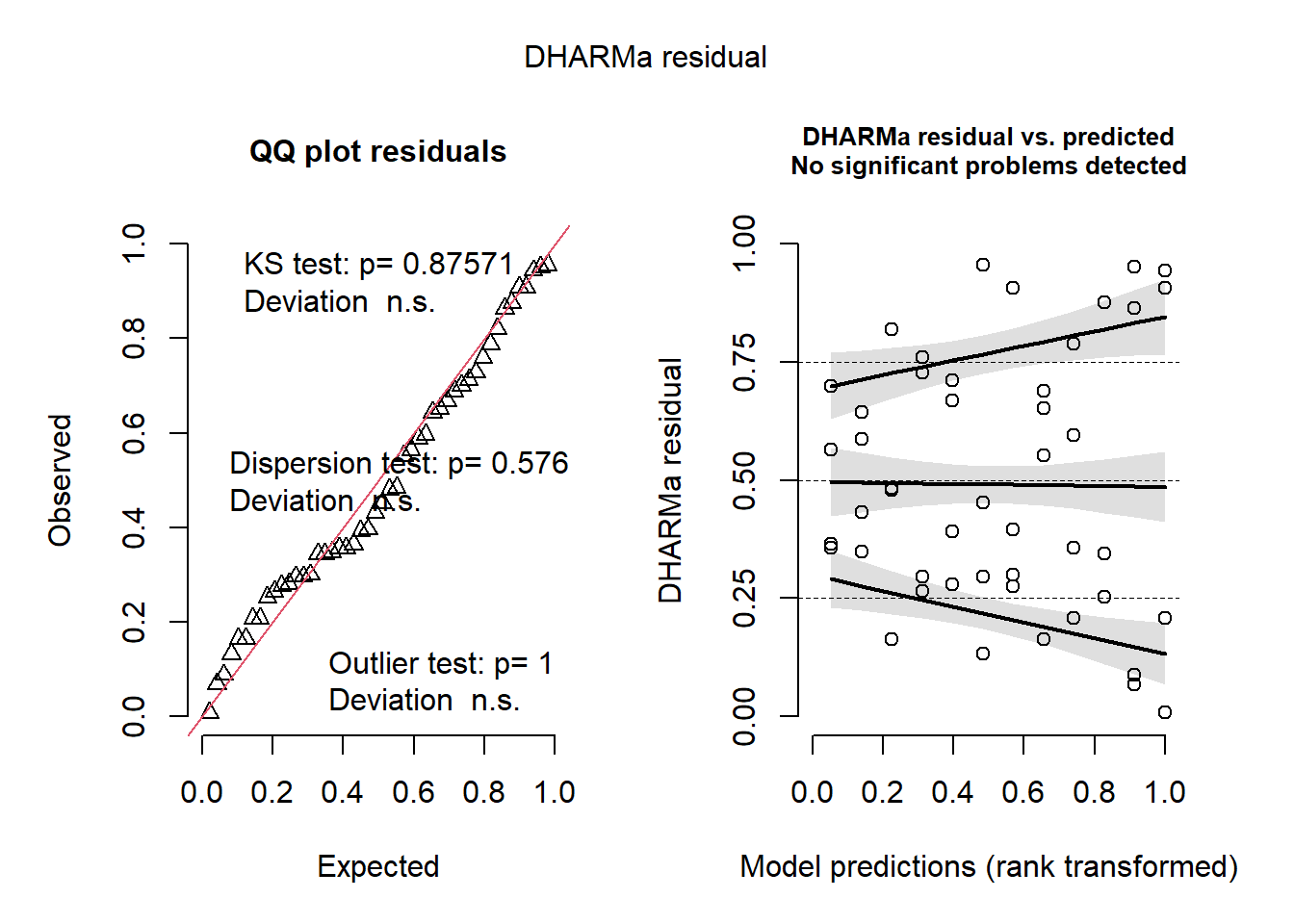
Diagnóstico com resíduos simulados
O pacote {DHARMa} usa simulação para avaliar os resíduos de modelos ajustados. Essa abordagem é útil porque resíduos simulados podem ser aplicados a diferentes classes de modelos.
desvios globais da distribuição esperada dos resíduos;
padrões entre resíduos e valores preditos;
possíveis valores extremos;
heterogeneidade de variância.
Em modelos lineares gaussianos simples, gráficos clássicos de resíduos também são úteis. Em modelos mistos, o diagnóstico por simulação fornece uma verificação adicional.
Médias marginais estimadas
As médias marginais estimadas, também chamadas de least-squares means ou estimated marginal means, são médias ajustadas pelo modelo. Elas são preferíveis às médias aritméticas simples quando há estrutura de delineamento, desbalanceamento ou efeitos adicionais no modelo.
As letras de agrupamento são uma forma compacta de apresentar comparações múltiplas. Grupos que compartilham a mesma letra não diferem estatisticamente ao nível adotado.
Neste material, usaremos a seguinte convenção:
letras minúsculas comparam híbridos dentro de cada método;
letras maiúsculas comparam métodos dentro de cada híbrido.
Note: adjust = "tukey" was changed to "sidak"
because "tukey" is only appropriate for one set of pairwise comparisons
letras_hibrido
# A tibble: 12 × 3
hybrid method letra_hibrido
<fct> <fct> <chr>
1 BG7049H pin a
2 30K64 pin a
3 30F53 YH pin ab
4 30F53 HX pin ab
5 30S31YH pin ab
6 30S31H pin b
7 BG7049H silk a
8 30K64 silk a
9 30F53 HX silk a
10 30F53 YH silk a
11 30S31H silk a
12 30S31YH silk a
Note: adjust = "tukey" was changed to "sidak"
because "tukey" is only appropriate for one set of pairwise comparisons
letras_metodo
# A tibble: 12 × 3
hybrid method letra_metodo
<fct> <fct> <chr>
1 30F53 HX silk A
2 30F53 HX pin A
3 30F53 YH pin A
4 30F53 YH silk A
5 30K64 pin A
6 30K64 silk A
7 30S31H silk A
8 30S31H pin B
9 30S31YH silk A
10 30S31YH pin A
11 BG7049H silk A
12 BG7049H pin A
Tabela final de médias ajustadas
Agora combinamos as médias estimadas com as letras de comparação.
tabela_medias <-as_tibble(emmeans(modelo_misto, ~ hybrid * method)) |>left_join(letras_hibrido, by =c("hybrid", "method")) |>left_join(letras_metodo, by =c("hybrid", "method")) |>mutate(letras =paste0(letra_hibrido, " ", letra_metodo),emmean =round(emmean, 1),SE =round(SE, 2),lower.CL =round(lower.CL, 1),upper.CL =round(upper.CL, 1) ) |> dplyr::select(hybrid, method, emmean, SE, lower.CL, upper.CL, letras)tabela_medias |>kable(col.names =c("Híbrido", "Método", "Média ajustada", "EP", "LI 95%", "LS 95%", "Letras"),caption ="Médias ajustadas do índice de infecção para cada combinação entre híbrido e método." )
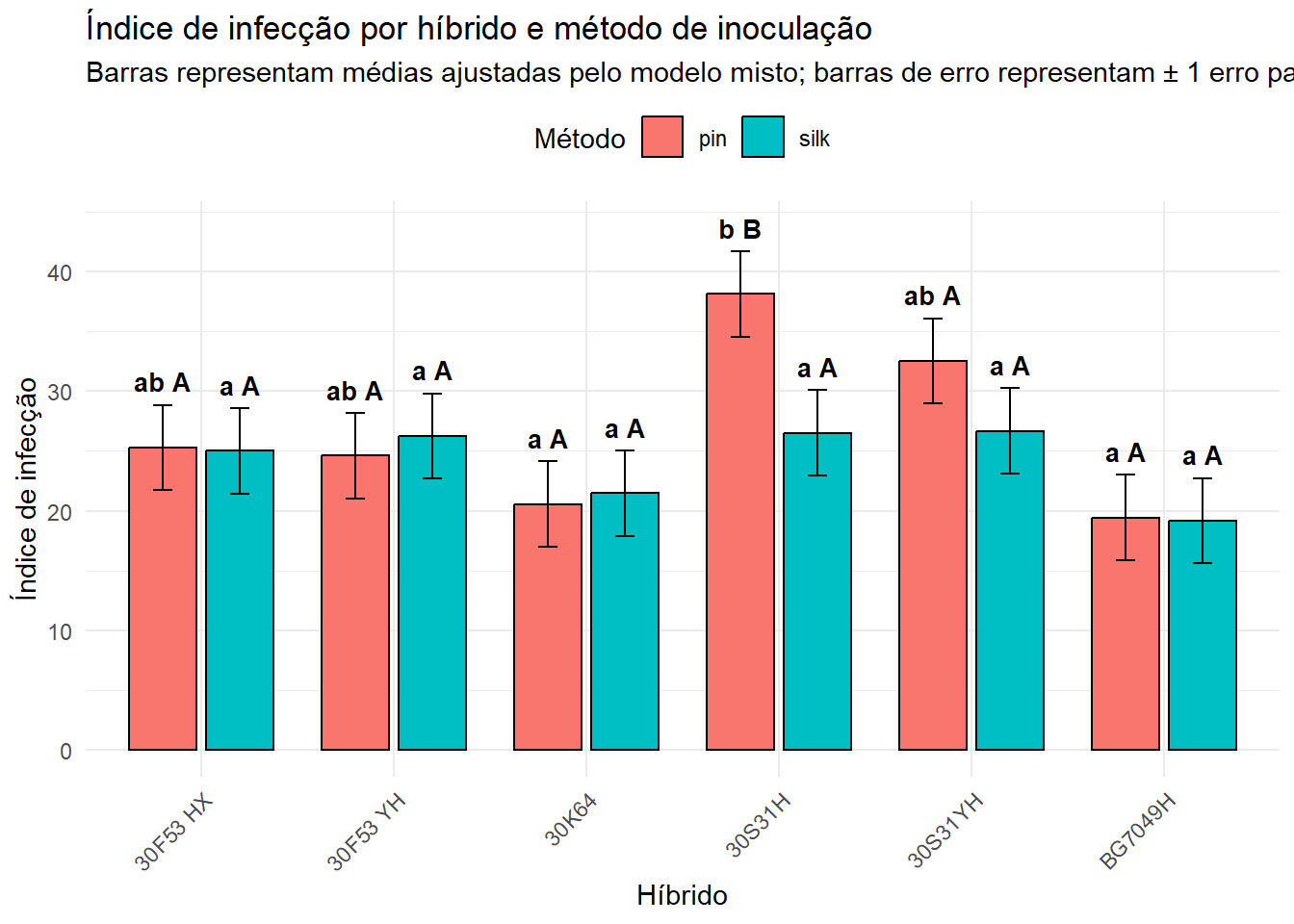
Médias ajustadas do índice de infecção para cada combinação entre híbrido e método.
Híbrido
Método
Média ajustada
EP
LI 95%
LS 95%
Letras
30F53 HX
pin
25.3
3.56
17.8
32.7
ab A
30F53 YH
pin
24.6
3.56
17.1
32.1
ab A
30K64
pin
20.6
3.56
13.1
28.0
a A
30S31H
pin
38.1
3.56
30.7
45.6
b B
30S31YH
pin
32.5
3.56
25.0
40.0
ab A
BG7049H
pin
19.4
3.56
12.0
26.9
a A
30F53 HX
silk
25.0
3.56
17.5
32.5
a A
30F53 YH
silk
26.2
3.56
18.8
33.7
a A
30K64
silk
21.5
3.56
14.0
28.9
a A
30S31H
silk
26.5
3.56
19.0
34.0
a A
30S31YH
silk
26.7
3.56
19.2
34.1
a A
BG7049H
silk
19.2
3.56
11.7
26.6
a A
A coluna emmean apresenta a média ajustada pelo modelo misto. O erro padrão (SE) expressa a incerteza associada à média estimada. Os limites lower.CL e upper.CL representam o intervalo de confiança de 95%.
Gráfico com médias ajustadas
O gráfico abaixo é construído a partir das médias ajustadas pelo modelo, não a partir de valores digitados manualmente. Essa é a abordagem recomendada porque evita erros de transcrição e torna o relatório reprodutível.
df_grafico <-as_tibble(emmeans(modelo_misto, ~ hybrid * method)) |>left_join(letras_hibrido, by =c("hybrid", "method")) |>left_join(letras_metodo, by =c("hybrid", "method")) |>mutate(letras =paste0(letra_hibrido, " ", letra_metodo),ymax = emmean + SE )ggplot(df_grafico, aes(x = hybrid, y = emmean, fill = method)) +geom_col(position =position_dodge(width =0.8),width =0.7,color ="black" ) +geom_errorbar(aes(ymin = emmean - SE, ymax = emmean + SE),position =position_dodge(width =0.8),width =0.2 ) +geom_text(aes(label = letras, y = ymax +2),position =position_dodge(width =0.8),size =3.5,fontface ="bold" ) +labs(x ="Híbrido",y ="Índice de infecção",fill ="Método",title ="Índice de infecção por híbrido e método de inoculação",subtitle ="Barras representam médias ajustadas pelo modelo misto; barras de erro representam ± 1 erro padrão" ) +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1),legend.position ="top" )
No gráfico, as barras representam as médias ajustadas pelo modelo misto. As barras de erro representam \(\pm 1\) erro padrão. As letras devem ser interpretadas de acordo com o contexto da comparação:
letras minúsculas: comparação entre híbridos dentro do mesmo método;
letras maiúsculas: comparação entre métodos dentro do mesmo híbrido.
Interpretação estatística
A interpretação deve seguir a estrutura do modelo. Se a interação híbrido × método for significativa ou biologicamente relevante, a comparação entre métodos deve ser feita dentro de cada híbrido, e a comparação entre híbridos deve ser feita dentro de cada método. Nesse caso, não é adequado apresentar apenas um efeito médio geral de método, pois esse efeito médio pode ocultar respostas específicas de cada híbrido.
Quando a interação não é significativa e também não há indicação biológica forte de respostas contrastantes, os efeitos principais podem ser interpretados com mais segurança. Mesmo assim, em experimentos agrícolas, a ausência de significância estatística não deve ser confundida com ausência absoluta de efeito. O tamanho do efeito, a precisão experimental e a relevância prática também precisam ser considerados.
Como relatar os resultados
Um parágrafo possível para relatar a análise seria:
O índice de infecção foi analisado considerando a estrutura de parcelas subdivididas, com híbridos nas parcelas principais e métodos de inoculação nas subparcelas. Foi ajustado um modelo linear misto com efeitos fixos de híbrido, método e sua interação, e efeitos aleatórios de bloco e parcela principal dentro de bloco. As médias ajustadas foram obtidas por emmeans, e as comparações múltiplas foram realizadas com ajuste de Tukey. Quando a interação híbrido × método foi relevante, os métodos foram comparados dentro de cada híbrido e os híbridos foram comparados dentro de cada método.
Extensão para produtividade
A mesma estrutura de análise pode ser usada para yield, substituindo a variável resposta no modelo.
A interpretação para produtividade deve considerar a pergunta biológica. Por exemplo, podemos perguntar se os métodos de inoculação alteram a produtividade, se os híbridos diferem em produtividade, ou se a resposta produtiva ao método depende do híbrido.
Pontos principais da aula
Experimentos em parcelas subdivididas possuem mais de um estrato de erro.
O fator da parcela principal e o fator da subparcela não devem ser testados usando o mesmo erro experimental.
Modelos mistos representam de forma natural a estrutura hierárquica do delineamento.
A interação entre fatores deve ser interpretada antes dos efeitos principais.
Médias ajustadas por modelo são preferíveis a médias simples quando há estrutura experimental.
Gráficos devem ser gerados a partir dos resultados do modelo, não digitados manualmente.
Referências
BATES, D.; MÄCHLER, M.; BOLKER, B.; WALKER, S. Fitting Linear Mixed-Effects Models Using lme4. Journal of Statistical Software, v. 67, n. 1, p. 1–48, 2015.
HOTHORN, T.; BRETZ, F.; WESTFALL, P. Simultaneous inference in general parametric models. Biometrical Journal, v. 50, n. 3, p. 346–363, 2008.
KUZNETSOVA, A.; BROCKHOFF, P. B.; CHRISTENSEN, R. H. B. lmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software, v. 82, n. 13, p. 1–26, 2017.
LEVENe, H. Robust tests for equality of variances. In: OLKIN, I. et al. (ed.). Contributions to Probability and Statistics. Stanford: Stanford University Press, 1960. p. 278–292.
LENTH, R. V. emmeans: Estimated Marginal Means, aka Least-Squares Means. R package, 2024.
PINHEIRO, J. C.; BATES, D. M. Mixed-Effects Models in S and S-PLUS. New York: Springer, 2000.
SHAPIRO, S. S.; WILK, M. B. An analysis of variance test for normality (complete samples). Biometrika, v. 52, n. 3–4, p. 591–611, 1965.
TUKEY, J. W. The Problem of Multiple Comparisons. Princeton: Princeton University, 1953.