A regressão linear simples é utilizada para modelar a relação entre uma variável dependente contínua (\(Y\)) e uma variável independente contínua (\(X\)). O modelo é representado pela equação: \[Y = \beta_0 + \beta_1 X + \epsilon\] Onde: - \(\beta_0\) é o intercepto (valor de \(Y\) quando \(X=0\)). - \(\beta_1\) é o coeficiente angular (inclinação da reta). - \(\epsilon\) é o erro residual.
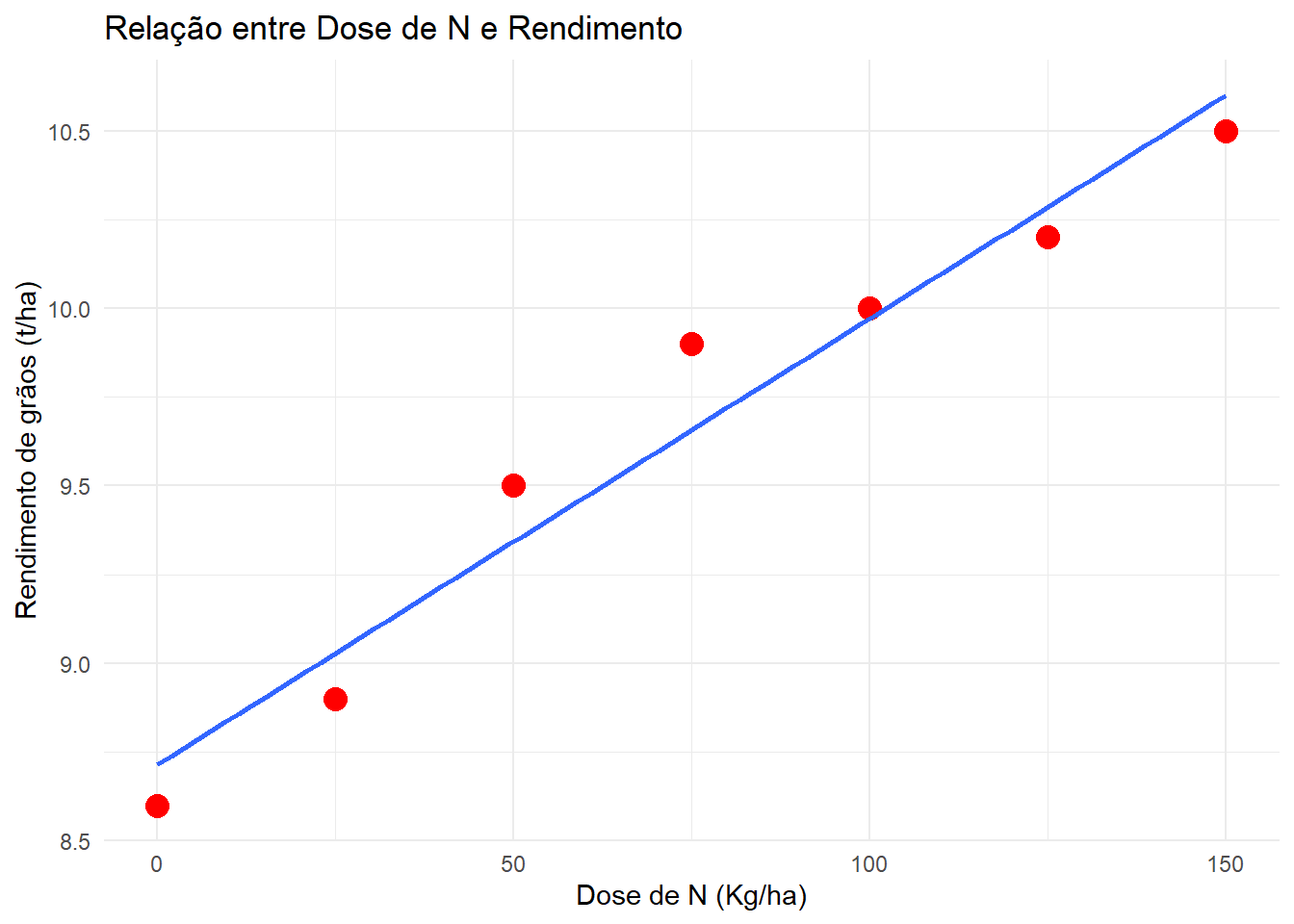
Exemplo 1: Rendimento vs. Dose de Nitrogênio
Neste exemplo, exploramos como a dose de nitrogênio influencia o rendimento de grãos.
library(tidyverse)library(rio)library(DHARMa)library(readxl)library(lme4)library(car)# Criação de um conjunto de dados simplesx <-seq(0, 150, by =25)y <-c(8.6, 8.9, 9.5, 9.9, 10, 10.2, 10.5)df <-data.frame(x = x, y = y)# Visualização inicial com linha de tendência linearggplot(df, aes(x, y)) +geom_point(size =4, color ="red") +geom_smooth(se =FALSE, method ="lm") +labs(title ="Relação entre Dose de N e Rendimento",x ="Dose de N (Kg/ha)",y ="Rendimento de grãos (t/ha)" ) +theme_minimal()
# Ajuste do modelo de regressão linear simplesm1 <-lm(y ~ x, data = df)# Resumo do modelo: interpretação dos coeficientes e R²# O R² indica a proporção da variância de Y explicada por X.summary(m1)
Call:
lm(formula = y ~ x, data = df)
Residuals:
1 2 3 4 5 6 7
-0.11429 -0.12857 0.15714 0.24286 0.02857 -0.08571 -0.10000
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.714286 0.110472 78.88 6.2e-09 ***
x 0.012571 0.001226 10.26 0.000151 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1621 on 5 degrees of freedom
Multiple R-squared: 0.9546, Adjusted R-squared: 0.9456
F-statistic: 105.2 on 1 and 5 DF, p-value: 0.0001513
# Predição manual para uma dose de 200 Kg/hax_new <-200y_pred <-coef(m1)[1] + (coef(m1)[2] * x_new)y_pred
(Intercept)
11.22857
# Verificação de valores preditos e resíduospred_df <- df |>mutate(predito =predict(m1),residual = y - predito )pred_df
# Coeficiente de correlação e R²r <-cor(df$x, df$y)r_sq <- r^2r_sq
[1] 0.9546351
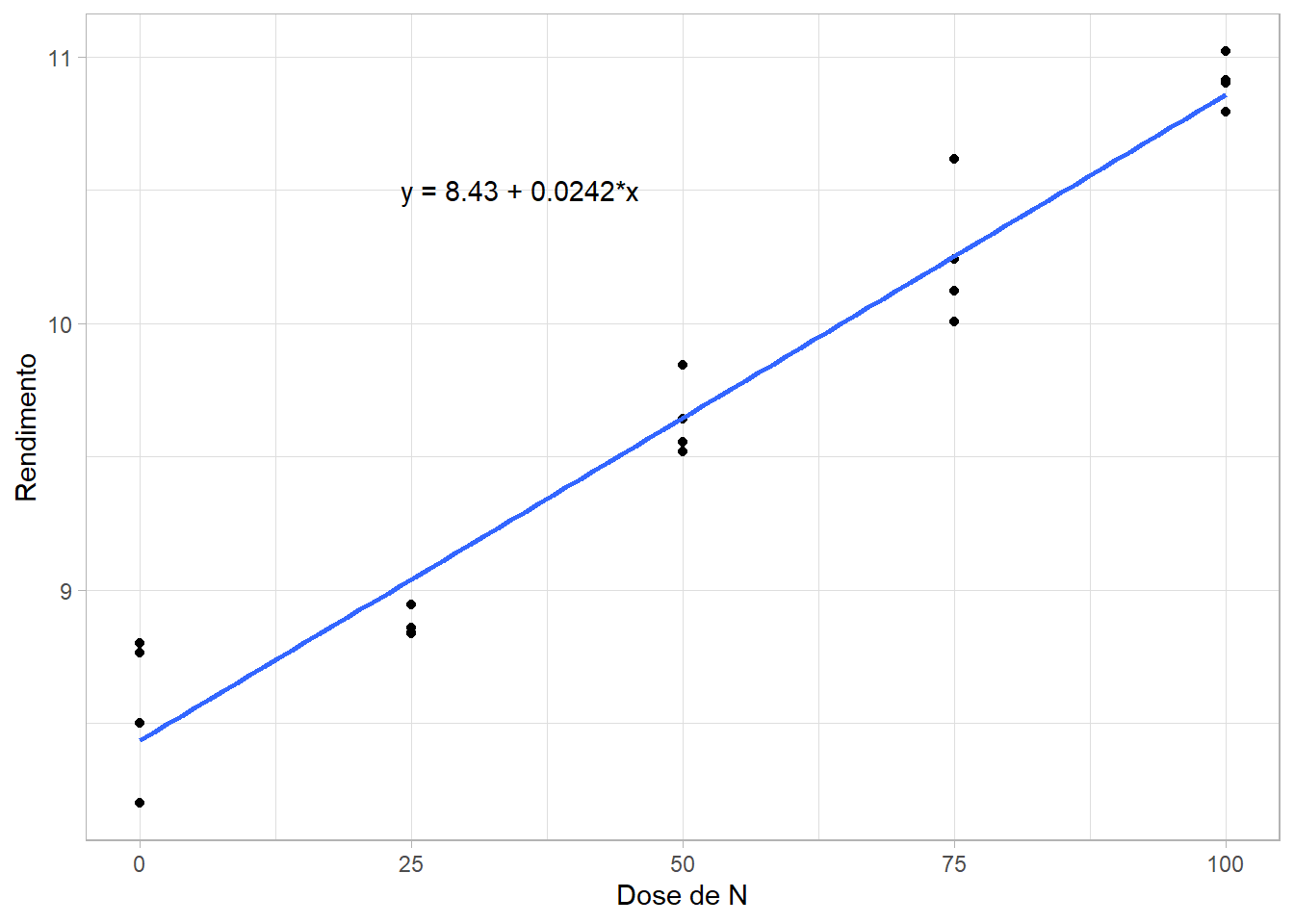
Regressão com Dados Externos
Utilizando dados de um experimento real para ajustar a regressão e adicionar a equação ao gráfico.
# Importação de dadosurl <-"https://bit.ly/df_biostat"df_reg <-import(url, sheet ="REG_DEL_DATA", setclass ="tbl")# Visualização com anotação da equação# A equação estimada é Y = 8.43 + 0.0242 * Xdf_reg |>ggplot(aes(DOSEN, RG)) +geom_point() +geom_smooth(se =FALSE, method ="lm") +annotate(geom ="text", x =35, y =10.5,label ="y = 8.43 + 0.0242*x" ) +labs(x ="Dose de N", y ="Rendimento") +theme_light()
`geom_smooth()` using formula = 'y ~ x'
# Ajuste e ANOVA do modelom2 <-lm(RG ~ DOSEN, data = df_reg)anova(m2)
Analysis of Variance Table
Response: RG
Df Sum Sq Mean Sq F value Pr(>F)
DOSEN 1 14.6676 14.6676 359.44 2.419e-13 ***
Residuals 18 0.7345 0.0408
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary(m2)
Call:
lm(formula = RG ~ DOSEN, data = df_reg)
Residuals:
Min 1Q Median 3Q Max
-0.24520 -0.14343 -0.03798 0.08990 0.36680
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.434550 0.078238 107.81 < 2e-16 ***
DOSEN 0.024222 0.001278 18.96 2.42e-13 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.202 on 18 degrees of freedom
Multiple R-squared: 0.9523, Adjusted R-squared: 0.9497
F-statistic: 359.4 on 1 and 18 DF, p-value: 2.419e-13
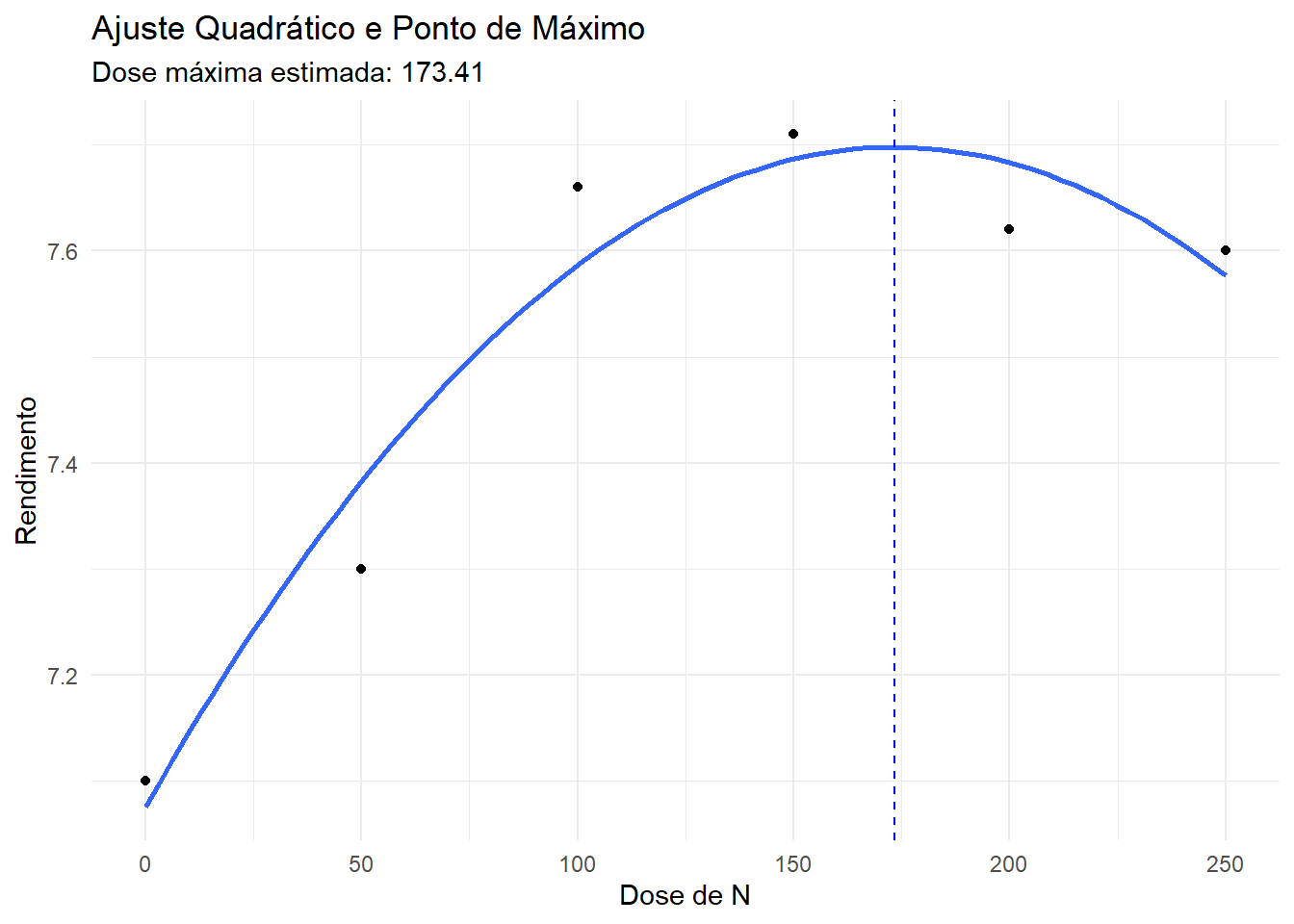
Regressão Polinomial (Quadrática)
Muitas vezes a resposta não é linear. O rendimento pode aumentar até certo ponto e depois estabilizar ou cair (lei dos retornos decrescentes). O modelo quadrático é: \[Y = \beta_0 + \beta_1 X + \beta_2 X^2 + \epsilon\]
A dose de máxima resposta econômica ou biológica pode ser calculada como \(X_{max} = -\beta_1 / (2 \beta_2)\).
# Dados com comportamento não-linearDOSEN <-c(0, 50, 100, 150, 200, 250)RG <-c(7.1, 7.3, 7.66, 7.71, 7.62, 7.6)df2 <-data.frame(DOSEN = DOSEN, RG = RG)# Ajuste do modelo quadrático (segundo grau)m4 <-lm(RG ~poly(DOSEN, 2, raw =TRUE), data = df2)summary(m4)
Call:
lm(formula = RG ~ poly(DOSEN, 2, raw = TRUE), data = df2)
Residuals:
1 2 3 4 5 6
0.02500 -0.08243 0.07371 0.02343 -0.06329 0.02357
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.075e+00 7.013e-02 100.882 2.15e-06 ***
poly(DOSEN, 2, raw = TRUE)1 7.184e-03 1.319e-03 5.445 0.0122 *
poly(DOSEN, 2, raw = TRUE)2 -2.071e-05 5.066e-06 -4.089 0.0264 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.07738 on 3 degrees of freedom
Multiple R-squared: 0.9389, Adjusted R-squared: 0.8982
F-statistic: 23.06 on 2 and 3 DF, p-value: 0.0151
# Extração dos coeficientes para cálculo do ponto de máximob0 <-coef(m4)[1]b1 <-coef(m4)[2] # Coeficiente linear (b)b2 <-coef(m4)[3] # Coeficiente quadrático (a)# Cálculo da Dose Máximadose_max <--b1 / (2* b2)dose_max
poly(DOSEN, 2, raw = TRUE)1
173.4138
# Visualização do modelo polinomialdf2 |>ggplot(aes(DOSEN, RG)) +geom_point() +geom_smooth(method ="lm", se =FALSE, formula = y ~poly(x, 2)) +geom_vline(xintercept = dose_max, linetype ="dashed", color ="blue") +labs(title ="Ajuste Quadrático e Ponto de Máximo",subtitle =paste("Dose máxima estimada:", round(dose_max, 2)),x ="Dose de N", y ="Rendimento" ) +theme_minimal()
Modelos Mistos e Multi-experimentos
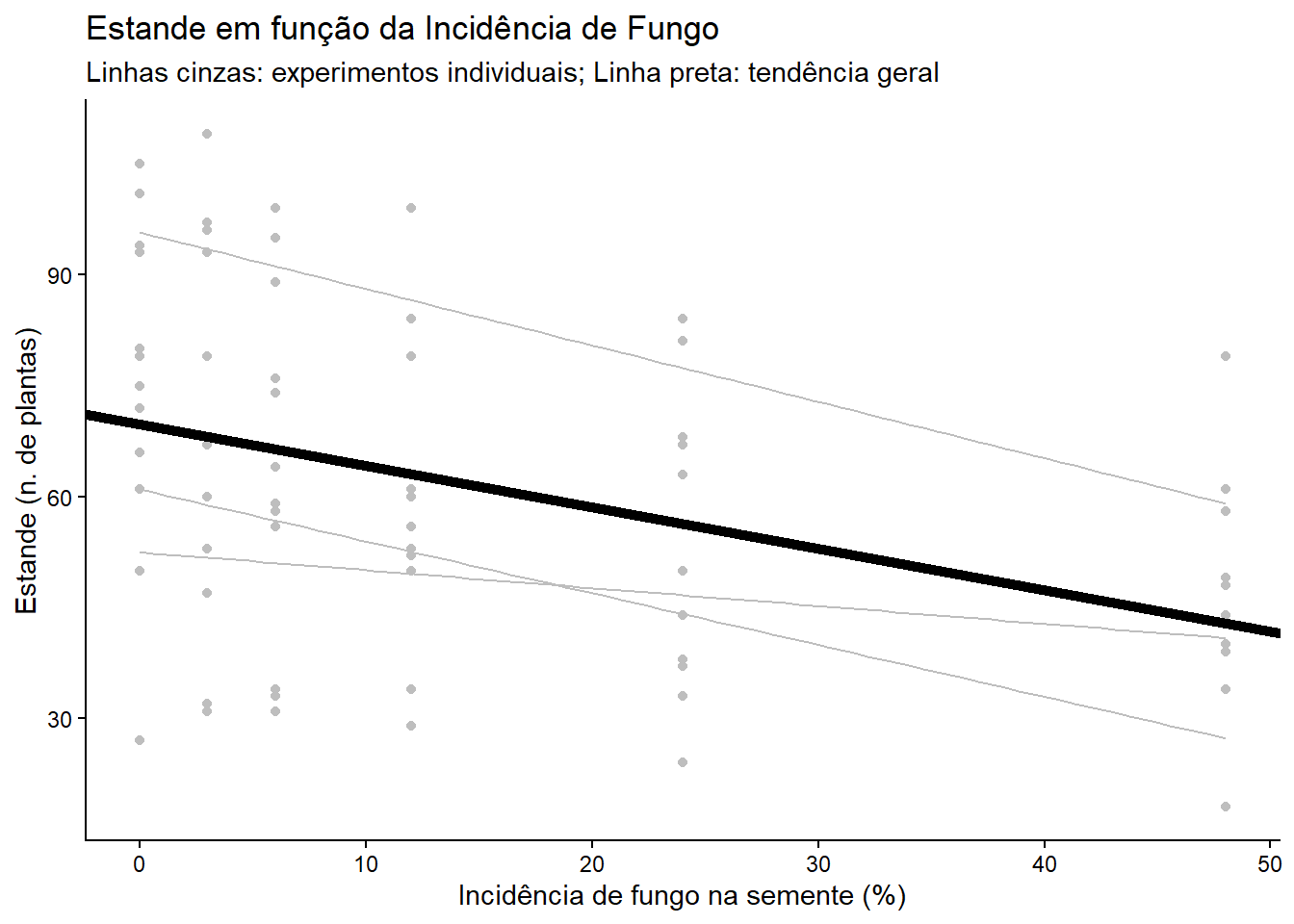
Quando temos dados de múltiplos experimentos ou locais, as observações dentro de cada experimento podem ser correlacionadas. Nesses casos, usamos Modelos Lineares Generalizados Mistos (GLMM) ou Modelos Mistos. - Efeitos Fixos: O tratamento de interesse (ex: incidência de fungo). - Efeitos Aleatórios: Fatores que representam uma amostra da população (ex: experimentos, blocos dentro de experimentos).
# Carregar dados de múltiplos experimentosestande <-read_excel("dados_diversos.xlsx", "estande")# Visualização dos experimentos individuaisestande |>ggplot(aes(trat, nplants, group = exp)) +geom_point(color ="gray") +geom_smooth(method ="lm", se =FALSE, color ="gray", size =0.5) +geom_abline(intercept =69.74, slope =-0.56, linewidth =2, color ="black") +theme_classic() +labs(title ="Estande em função da Incidência de Fungo",subtitle ="Linhas cinzas: experimentos individuais; Linha preta: tendência geral",x ="Incidência de fungo na semente (%)", y ="Estande (n. de plantas)" )
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
`geom_smooth()` using formula = 'y ~ x'
# Análise por experimento (Abordagem clássica)# Experimento 1exp1 <- estande |>filter(exp ==1)m_exp1 <-lm(sqrt(nplants) ~ trat + bloco, data = exp1)anova(m_exp1)
Analysis of Variance Table
Response: sqrt(nplants)
Df Sum Sq Mean Sq F value Pr(>F)
trat 1 1.5431 1.5431 2.5291 0.1267040
bloco 1 13.9342 13.9342 22.8386 0.0001012 ***
Residuals 21 12.8125 0.6101
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Analysis of Variance Table
Response: sqrt(nplants)
Df Sum Sq Mean Sq F value Pr(>F)
trat 1 12.2843 12.2843 34.991 5.94e-06 ***
Residuals 22 7.7236 0.3511
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# ABORDAGEM DE MODELO MISTO# Tratamos 'exp' e 'bloco' como efeitos aleatórios# A notação (1 | exp/bloco) indica blocos aninhados dentro de experimentosm_mix <-lmer(nplants ~ trat + (1| exp/bloco), data = estande)# Resultados do modelo mistosummary(m_mix)
Linear mixed model fit by REML ['lmerMod']
Formula: nplants ~ trat + (1 | exp/bloco)
Data: estande
REML criterion at convergence: 575.8
Scaled residuals:
Min 1Q Median 3Q Max
-2.21697 -0.63351 0.04292 0.67094 1.92907
Random effects:
Groups Name Variance Std.Dev.
bloco:exp (Intercept) 54.76 7.40
exp (Intercept) 377.43 19.43
Residual 134.99 11.62
Number of obs: 72, groups: bloco:exp, 12; exp, 3
Fixed effects:
Estimate Std. Error t value
(Intercept) 69.74524 11.57191 6.027
trat -0.56869 0.08314 -6.840
Correlation of Fixed Effects:
(Intr)
trat -0.111
car::Anova(m_mix) # Teste de Wald para efeitos fixos