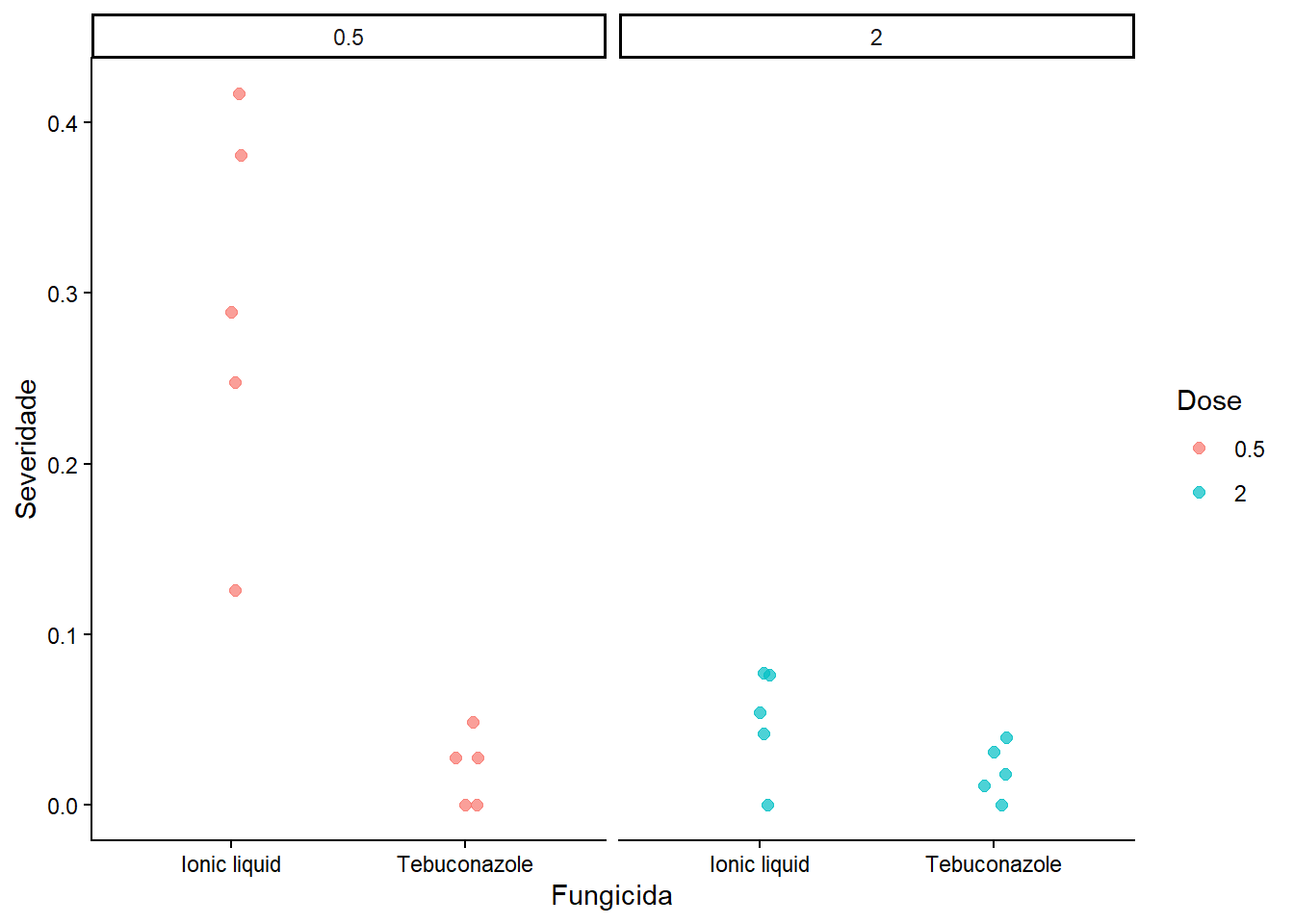
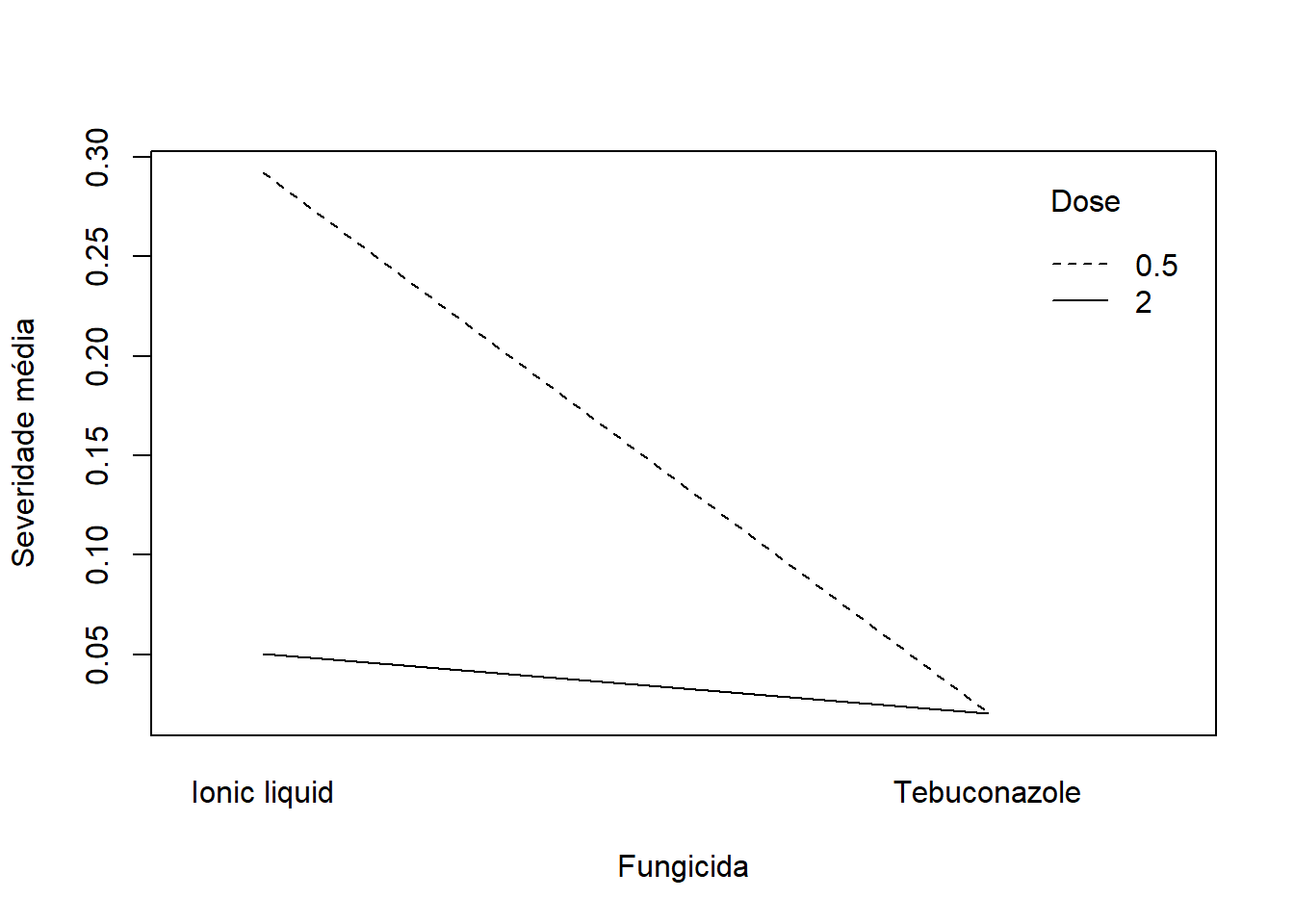
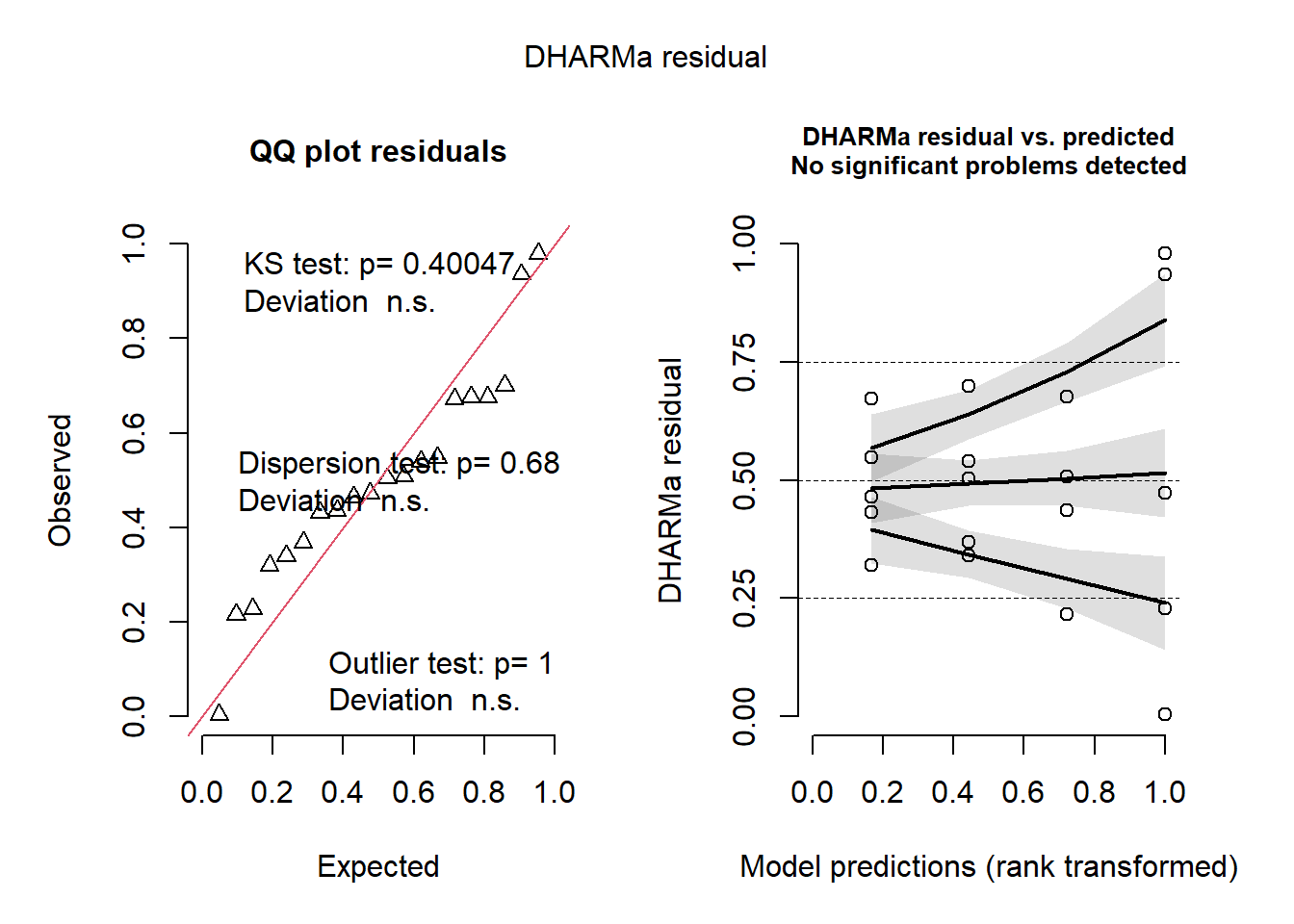
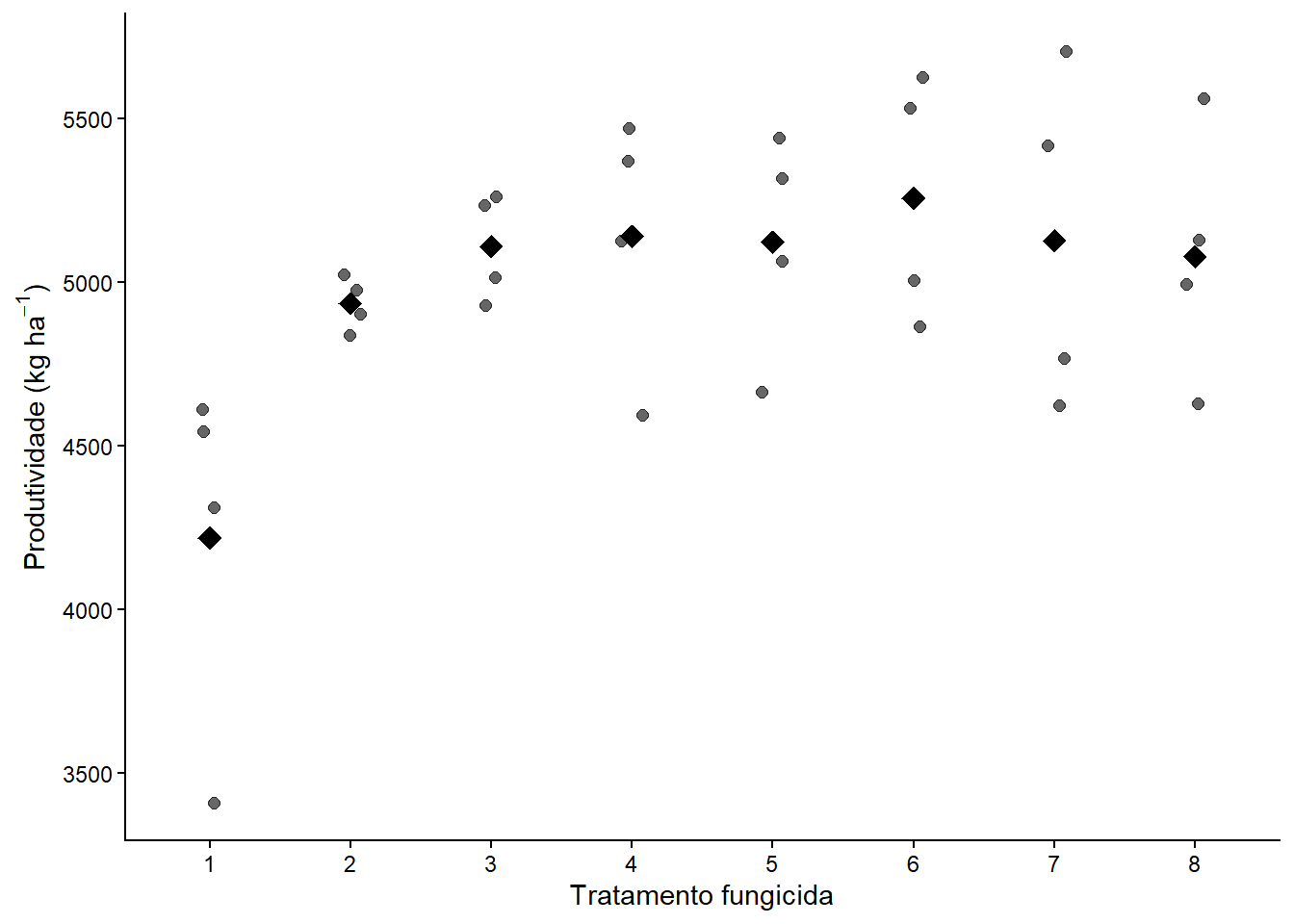
library(readxl)
library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.2.0
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.5 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(emmeans)Warning: package 'emmeans' was built under R version 4.5.3Welcome to emmeans.
Caution: You lose important information if you filter this package's results.
See '? untidy'library(multcomp)Warning: package 'multcomp' was built under R version 4.5.3Loading required package: mvtnormWarning: package 'mvtnorm' was built under R version 4.5.3Loading required package: survival
Loading required package: TH.dataWarning: package 'TH.data' was built under R version 4.5.3Loading required package: MASS
Attaching package: 'MASS'
The following object is masked from 'package:dplyr':
select
Attaching package: 'TH.data'
The following object is masked from 'package:MASS':
geyserlibrary(DHARMa)Warning: package 'DHARMa' was built under R version 4.5.3This is DHARMa 0.4.7. For overview type '?DHARMa'. For recent changes, type news(package = 'DHARMa')library(ggthemes)Warning: package 'ggthemes' was built under R version 4.5.3